测评人:刘诚,钱鑫宇,张乐恒
第一部分:前言与测评方案
1.1 测评背景
随着大语言模型(LLM)技术的爆发式增长,软件开发领域正经历着一场前所未有的范式转移。AI辅助编程工具已从早期简单的代码片段补全,进化为具备深度上下文理解、自主代理能力的集成开发环境。传统的IDE主要依赖开发者手动编写代码、搜索文档和调试错误,而新一代AI IDE(如Cursor、Windsurf等)试图通过内嵌大模型,实现从“辅助编写”到“自主生成与重构”的跨越。
然而,市场上的AI IDE产品良莠不齐。部分产品仅停留在API调用的层面,缺乏对项目整体架构的理解,导致生成的代码片段难以融入现有工程,甚至引入隐蔽的Bug;而头部产品已经开始尝试Agent模式,能够自主完成文件检索、依赖配置和多文件协同修改。在这一背景下,建立一套标准化、可量化的测评体系显得尤为迫切。我们需要客观评估这些工具在真实开发场景中的表现,包括其对复杂需求的理解能力、对大型代码库的重构能力以及在实际工作流中的提效程度。本报告旨在通过多维度的实测数据,为开发者选择工具提供依据,并揭示AI辅助开发未来的演进方向。
1.2 测评总纲
本次测评采用五级评分制作为定性评价标准,用于界定各细项的体验层级;同时采用百分制作为IDE最终评分的定量标准。
定性评价层级(五级评分制):
- 1级(夯):体验极佳,基础扎实,功能完善,无感知的智能化体验。
- 2级(顶级):表现优秀,处于行业领先地位,偶有瑕疵但不影响核心体验。
- 3级(人上人):体验良好,能满足大部分需求,但在复杂场景下有优化空间。
- 4级(NPC):功能存在但体验平庸,甚至有明显缺陷,如同工具人般机械。
- 5级(拉):体验极差,功能不可用或严重阻碍开发流程。
定量评分总分(100分制): 本测评体系共包含五大维度,累计满分100分。具体分值分布见下文。
1.3 测评维度与评分标准详解
一、美观度及个性化程度(10分)
本维度主要考察IDE的界面设计美学、交互逻辑以及用户自定义空间的广度。
| 细分维度 | 评分标准与说明 |
|---|---|
| 界面布局与美观 | 1级(夯):界面整洁美观,功能模块布局符合直觉,视觉设计现代化。2级(顶级):界面清晰,主要功能易于查找。3级(人上人):界面中规中矩,无明显设计亮点,但不影响使用。4级(NPC):界面拥挤或陈旧,按键逻辑混乱。5级(拉):界面丑陋,严重影响使用心情。 |
| 个性化调整能力 | 1级(夯):支持高度个性化调整,主题、快捷键、布局均可自定义,且配置难度低。2级(顶级):支持主流的个性化设置,满足大部分用户需求。3级(人上人):支持部分调整,但配置较为繁琐。4级(NPC):几乎不支持个性化,只能使用默认设置。5级(拉):强制绑定特定布局,无法适应用户习惯。 |
二、使用难度(10分)
本维度考察IDE的入门门槛与环境搭建效率。
| 细分维度 | 分值 | 评分标准细则 |
|---|---|---|
| 安装配置的耗时 | 3分 | 3分:10MB/s下安装时间在2分钟内,一键配置,图形化界面。2分:整体耗时较长,配置要求复杂,但有官网说明教程,可以接受。1分:配置要求过高,需要自行找使用方式。0分:一般人很难自主完成配置。 |
| 学习使用的难度 | 3分 | 3分:内嵌教程,上手简单,操作基本可以可视化完成或通过agent完成。2.5分:有简短清晰的使用说明且易于操作。2分:有说明文档,文档详细,但过长,对新手不友好。1分:说明长且杂乱,难以理解。0分:一般人难以自主上手。 |
| 配套社区/插件 | 4分 | 4分:有官方社区,其中有许多人经常活跃,推送产品更新信息。3分:有官方社区,有用户交流,能了解产品更新。2分:有官方社区,但活跃度低。1分:无官方社区。0分:基本无法找到相关社区。 |
三、核心功能 - 基础性能(20分)
本维度考察IDE作为开发工具的基本素质。
| 细分维度 | 分值 | 评分标准细则 |
|---|---|---|
| 启动速度 | 2分 | 依据实际体验主观打分(启动快慢、卡顿情况)。 |
| 多项目切换 | 4分 | 依据实际体验主观打分(切换流畅度、状态保留能力)。 |
| 代码补全 | 14分 | 14分:实时跟随,深度理解用户意图,不易误触,且能自动补充详细注释。12分:实时跟随,深度理解用户意图,代码补全方便,且不易误触。9分:能对编辑内容进行实时跟随,深度理解用户可能需求的代码。5分:能对编辑内容进行跟随,基本理解用户可能需求的代码。0分:有代码补全的功能,但不好用。 |
四、核心功能 - 代理模式(40分)
本维度是测评的核心,考察AI Agent对需求的理解、文件处理能力、任务完成度及自主调试能力。
| 细分维度 | 分值 | 评分标准细则 |
|---|---|---|
| 功能实现 | 20分 | 20分:完全可以理解用户需要的功能,甚至可以完善用户需求,实现复杂任务,自主调试、完善,用户直接获得良好成品。17分:可以理解用户需要的功能,实现复杂任务,自主调试,产出基本满足需求。14分:基本理解需求,实现较复杂任务,小Bug需用户提示修正。8分:基本理解需求,但有明显遗漏,仅完成简单任务,产出有Bug。0分:不能实现功能或出现大量Bug。 |
| 内嵌工作流 | (含于上项) | 评判依据:是否自动划分任务、监视进度、自动搜索读取文件、配置依赖、自动生成测试与调试。 |
| 错误调试 | 10分 | 10分:快速定位并正确修改,给出正确说明。9分:能找到错误进行修改,自主研究循环直到改正。7分:在用户提示下可以寻找到错误并改正。3分:找不到真正错误,反复改无关紧要的内容。0分:改掉正确内容,出现更多Bug。 |
| 代码重构 | 5分 | 5分:重构后效率提升,内存占用减少,逻辑优化。4分:重构后效率提升,减少不必要计算。3分:仅合并重复代码。1分:影响原有功能或性能下降。0分:重构后无法运行。 |
五、其它任务能力(20分)
| 细分维度 | 分值 | 评分标准细则 |
|---|---|---|
| 多语言支持 | 2分 | 2分:支持多种通用语言。1.5分:在插件辅助下支持多语言。0分:仅支持特定语言。 |
| 多平台使用 | 2分 | 2分:全平台覆盖,体验一致。1.5分:仅PC端。0分:单一平台。 |
| 开发多平台项目 | 3分 | 3分:支持开发全平台及小程序等项目。2.5分:支持开发全平台项目。2分:仅支持PC端项目开发。0分:仅支持单一平台。 |
| 团队协作支持 | 3分 | 依据实际功能打分(如代码审查、协作冲突处理等)。 |
| 模型支持 | 5分 | 考察是否支持主流模型接入。 |
| 使用价格 | 5分 | 考察免费额度、订阅费用性价比。 |
第二部分:IDE分项测评
2.0 整体测评省流版
一、评分
根据上述的评价细则,我们对IDE进行了打分。核心功能包括代码补全、功能实现、bug修改、代码重构。
鉴于审美是需要由群众决定,我们通过问卷的形式,调查了大家对于各个IDE的看法,形成了调查问卷。但是由于调查对象大多是大学生,且只收回33份问卷,调查结果可能有偏差,仅供参考。以下是部分重要参数的表格,完整的积分表见附件。
| IDE | 总评 | 核心功能 | 美观度 | 定价 |
|---|---|---|---|---|
| Trae国内版 | 76 | 39 | 10 | 4 |
| Trae国际版 | 74 | 40 | 10 | 4 |
| 通义灵码 | 74 | 43 | 8 | 3 |
| Qoder | 80 | 49 | 8 | 2 |
| Copilot | 71.5 | 30 | 8 | 5 |
| Windsurf | 85 | 52 | 6 | 3 |
| Cursor | 81.5 | 49 | 3 | 2 |
根据总评,我们推荐使用 windsurf 和 qoder 作为主力开发,如果预算充足,cursor 也是高性能的选择。当然,国内的新手用户使用 trae 也是不错的选择。
二、闪光点
在具体评分之外,不少应用的闪光点必须被提出,防止埋没在分数的框架中。
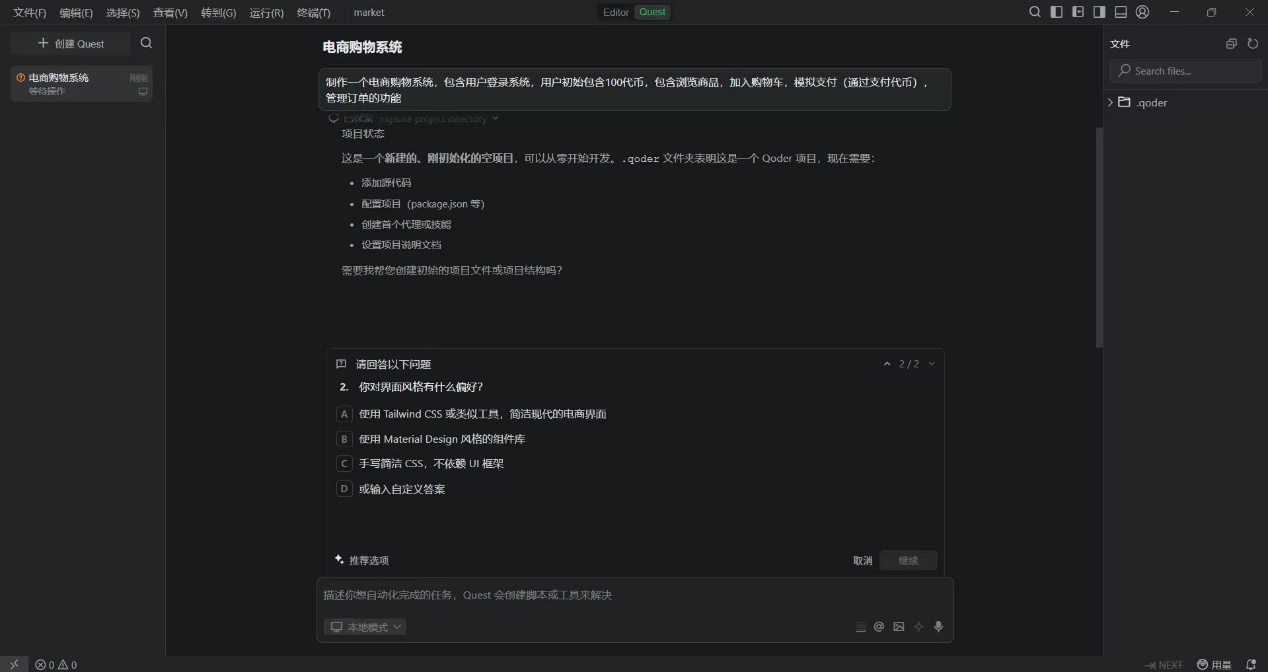
- 阿里系的通义灵码和qoder:拥有quest模式,方便实现从无到有的应用创建,对有想法但缺乏经验的新人极度友好,在灵感落地/工程开发上具有极大的帮助。
- Qoder:拥有repo wiki功能,能主动将大文件夹中的内容整理为知识库,在大型项目开发中有重要作用。
- Windsurf、qoder:在整理用户需求的时候,不仅会理解用户需求,更能主动向用户提问,进一步帮助用户明确需求。
- Trae:可以图形化自定义智能体,对于不同功能实现针对,方便用户自定义工作流。
- Cursor:内嵌类似于git的版本控制系统,便于版本管理、多人协作。
2.1 测评对象:Trae国内版(钱鑫宇)
一、IDE简介
TRAE是字节开发的AI IDE,其能够理解需求、调用工具并独立完成各类开发任务的“AI 开发工程师”,帮助你高效推进每一个项目,覆盖从编码、调试到测试、重构、部署等多类开发任务提供个人版与企业版两种形态,面向不同用户规模与使用场景,满足从个人开发到企业级协作的多样化需求。
二、评价概况
界面美观:夯
安装配置的耗时:夯
学习使用的难度:顶级
配套社区/插件:人上人
启动速度:夯
多项目切换:顶级
代码补全:顶级
功能实现:人上人
错误调试:NPC
代码重构:顶级
多语言支持:顶级
多平台支持:顶级
团队协作支持:顶级
模型支持:NPC
使用价格:顶级
三、具体评价
界面布局
Trae包含solo模式与IDE模式,由项目文件夹,编辑器,AI对话框组成。 Solo模式与IDE模式并无本质不同,只是AI对话框和项目文件夹位置对换,其介绍中solo模式性能更佳,solo模式下按键简洁,数量较少,IDE模式与VScode基本一致。
使用难度
Trae可以直接在官网下载,无复杂操作,使用简单。 社区方面,Trae有官网社区,其中包含新手入门与大量案例,介绍比较详细,也有许多社区贡献者和线上线下活动,但无法获知贡献者做了什么,Trae在飞书上的社区显示有上万订阅。
代码补全
Trae的代码补全速度快,用 Tab 键和绿色标志,根据情况不预测或预测一行或多行甚至一整块代码内容,但是有时会遮挡代码,导致正常写入有点受影响,且基本不会补写注释,在修改时能预测接下来的相关的接近修改,对于跨文件的变量名,在点开其他文件之后会有显示。
代理模式
Trae的solo模式允许接入GLM,kimi等共7个模型,IDE模式多了ds和qwen和一个新版本,两种模式都可以调为自动选择最合适的模型,都可以自行设置智能体,IDE形态下有3个内置智能体,solo只有一个,但对代码的处理能力更强,自行添加的智能体允许一万字以内的提示词描述。输入指令后,Trae会生成任务流程,一步一步完成,配置和运行可直接进行,调试需要创建launch.json文件进行,其编写代码往往会实现要求但达不到用户的心理预期,因为其往往按照要求的最低标准完成任务,但一定程度上也会创建美观界面和部分优良功能。
Debug
Trae找错误时通常能找到错误,但有时会认为错误在某一点,忽略其他部分内容,导致需要经过多轮对话才能找到。
定价
Trae个人版免费,企业版有基础,团队,旗舰3个版本,分别要49,99,199元每席每月,基础版本加入了30M 会话 Tokens + 10M 补全 Tokens和企业版专用推理服务,团队版本加入了40M 会话 Tokens + 20M 补全 Tokens,企业自定义 Agent,企业数据,安全管控和优先体验国内 SOTA 模型,旗舰版本加入了50M 会话 Tokens + 40M 补全 Tokens, CLI 全形态,用量精细管控和IP白名单管理等功能。
其他
Trae支持Windows,Linux,Macs,支持中英双语,支持企业整体管理,便于团队协作。
2.2 测评对象:Trae国际版(张乐恒)
一.IDE简介
Trae 是字节跳动(ByteDance)面向国际市场推出的下一代 AI 原生 IDE。它基于 VS Code 二次开发,旨在通过“自适应 AI 代理”来挑战 Cursor 的霸主地位。不同于传统的 Copilot,Trae 主打“Builder”模式,强调 AI 不仅能写代码,还能自主运行终端、自我修复错误。然而,在真实的高难度重构测试中,这种“自主性”目前表现为把双刃剑。
二.评价概况:
- 界面美观:夯
- 安装配置的耗时:顶级
- 学习使用的难度:顶级
- 配套社区/插件:npc
- 启动速度:夯
- 多项目切换:顶级
- 代码补全:顶级
- 功能实现:顶级
- 错误调试:npc
- 代码重构:顶级
- 多语言支持:夯
- 多平台支持:顶级
- 团队协作支持:顶级
- 模型支持:npc
- 使用价格:夯
三.具体评价
界面布局: Trae 的设计语言紧随主流,保持了 VS Code 的熟悉感。 Editor 模式中规中矩,但在侧边栏的设计上,Trae 整合了 Chat 和 Builder(构建器)两个入口。 Builder 模式是其核心差异化功能。不同于 Cursor Composer 的“悬浮窗+极速应用”风格,Trae 的 Builder 更像是一个“全托管的实习生”。它倾向于展示完整的“思考-修改-测试”链路。但在实测中,这种布局在处理长任务时显得略显臃肿,用户不得不盯着 AI 在终端里反复尝试,无法快速干预。
使用难度: 配置非常简单,支持一键导入 VS Code 配置。 然而,在交互体验(UX)上,Trae 给用户的心智负担较重。在 Task 2(Bug 修复)测试中,Trae 容易陷入“长考”(Long Thinking),并且在终端测试中“出不来”。这使得用户从“监督者”变成了“等待者”,使用难度体现在对 AI 行为的不可控性上,同时,使用者经常会收到需要删除测试文件的提示。
代码补全: Trae 的行内补全速度极快(得益于字节跳动强大的后端推理基建),在单文件、短逻辑的补全上,反应灵敏度不输 Cursor。 跨文件感知上,其上下文索引策略覆盖了业务代码,测试文件和边缘逻辑的关联度上也比较精准。
代理模式(Builder / Agent Workflow):
这是本次 Excalidraw 测试中欠缺的部分。Trae 的 Agent 表现出“过度工程化”的特征:
重构任务(Refactoring): 在 Task 2(添加字段)中,Trae 初次修改遗漏了关键文件(如 restore.ts),评分 3.8/5。 但在自我修复环节,它遭遇了滑铁卢。当用户甩回报错后,Trae 陷入了死循环。它试图自主运行测试 -> 报错 -> 尝试修复 -> 再运行测试 -> 再报错。这种“陷入终端测试出不来”的现象,说明其 Agent 的“停止机制”和“错误反思能力”尚不成熟。它试图完美解决所有问题,却因无法处理复杂的测试环境配置而卡死。
新功能开发(Feature): 在 Task 3(Toolbar 统计按钮)中,Trae 虽然成功完成了任务,但过程极其低效。
- Cursor: 并在几秒钟内定位文件 -> 生成 UI -> 结束。
- Trae: 生成了大量的临时测试文件,思维链极长,反复验证逻辑。虽然最终结果是好的,但耗时是 Cursor 的数倍。这给人的感觉是“用力过猛”——杀鸡用牛刀,导致开发流畅度大打折扣。
定价角度:
Trae 目前处于市场推广期,提供低门槛的早鸟体验。 对于个人开发者来说,这是一个极大的诱惑。你可以在 3usd/m 的价格体验到 Gemini3-pro 等顶级模型。我认为这个价格对于个人来说已经是非常舒适了,并且体验下来,对于小型项目是能完全驾驭的,大型项目效率略有下降,但考虑其价格,完全可以接受。
模型角度:
Trae 支持 Gemini,Grok-4 等模型,但对于 GPT 系列和 Claude 系列的模型还没有直接服务提供,需要自己接入 api。
其他维度:
Trae 在多语言支持(特别是中文)方面做得很好。
2.3 测评对象:通义灵码(钱鑫宇)
一、IDE 简介
通义灵码是阿里巴巴制造的 IDE,提供代码智能生成、智能问答、多文件修改、编程智能体等能力,为开发者带来高效、流畅的编码体验,引领 AI 原生研发新范式。为企业客户提供了企业标准版、专属版,具备企业级场景自定义、私域知识增强等能力,助力企业研发智能化升级。
二、评价概况
界面美观:顶级
安装配置的耗时:夯
学习使用的难度:顶级
配套社区/插件:NPC
启动速度:夯
多项目切换:人上人
代码补全:顶级
功能实现:人上人
错误调试:顶级
代码重构:顶级
多语言支持:顶级
多平台支持:人上人
团队协作支持:顶级
模型支持:NPC
使用价格:人上人
三、具体评价
界面布局
通义灵码包含Editor与quest模式,Editor界面与VScode出最右端AI对话框外,基本无明显不同,Quest模式左侧有对话框,右侧有编辑器,但没有文件目录
使用难度
通义灵码可以直接在官网下载,也可以在VScode中获取插件 通义灵码社区有视频课程,但案例不是Trae那种使用方法,而是商业性质的使用情况,视频课和互动都在阿里云平台上,平台上有详细文档介绍产品和使用方法以及问题排查指南
代码补全
通义灵码的代码补全速度快,用绿色标志,根据情况不预测或预测一行或多行甚至一整块代码内容,基本不会遮挡代码,但基本不会补写注释,在基本不影响代码的地方分行,有时会预测注释
代理模式
通义灵码智能体Editor无法接入其他模型,只有智能体和智能问答,在输入指令后,有时会通过问卷了解需求,会生成任务流程,一步一步完成,配置和运行可直接进行,调试需要创建luanch.json文件进行,其编写代码往往会实现要求但达不到用户的心理预期,因为其往往按照要求的最低标准完成任务,但一定程度上也会创建美观界面和部分优良功能,Quest模式有Spec,性能显著强于Editor模式,对大文件的处理能力也显著增强
Debug
Editor下较难找到大文件中的所有错误,Quest能力显著增强
定价
通义灵码个人基础版代码生成次数受限,59元每月的个人专业版仅解除这一限制,企业标准版79元每人每月,加入RepoWiki(Beta)和企业专有功能,企业专属版159元每人每月,加入多组织管理,专属YPC,IP白名单和专有网络访问,按照官网显示,各版本基础性能基本一致
其他
通义灵码支持Windows,Macs和JetBrains获取,支持中英双语,支持企业整体管理,便于协作
2.4 测评对象:qoder(刘诚)
一、IDE简介
Qoder 是由阿里巴巴倾力打造的一款企业级 AI IDE。它深度集成阿里云生态,凭借多智能体(Multi-Agent)架构与云端沙箱环境,能够自主处理复杂的编程长任务。该平台支持十万级超大规模工程的精准索引,并结合独有的 RepoWiki 知识图谱,使 AI 能够像资深架构师一样理解项目背景,实现超 80% 的记忆有效率。Qoder 不仅提升了代码生成速度,更通过全链路的智能协同,重新定义了真实业务场景下的软件开发范式
二、评价概况
界面美观:顶级
安装配置的耗时:顶级
学习使用的难度:顶级
配套社区/插件:人上人
启动速度:夯
多项目切换:人上人
代码补全:顶级
功能实现:顶级
错误调试:夯
代码重构:夯
多语言支持:夯
多平台支持:顶级
团队协作支持:夯
模型支持:人上人
使用价格:人上人
三、具体评价
界面布局: Qoder采用双功能的形式,包括更传统的editor和更简介的quest模式,用户可以方便地在两个模式中进行切换。其图标按钮总体风格简介明了,便于操作。 Editor模式下,其主要风格类似VScode,传统使用VScode的开发者可以很快熟悉操作界面。 Quest模式下,整个界面由项目文件夹和AI对话窗口组成,充分发挥AI在IDE中的作用,弱化了传统的面对代码的编程方式,而是在扩展窗口中放置代码块。
使用难度: 配置本身并不麻烦,不需要麻烦的操作,可以从常用的IDE中导入配置,上手即用 在社区方面,qoder拥有官方论坛,虽然比较活跃,但是论坛中更多地是对定价活动的吐槽,对于技术问题的讨论和对于新人的支持并不多。此外,qoder在github上有社区项目,用于分享agent的技能和配置,但是门槛较高。 其网站包含相关文档,文档内容较为详细,但是网页内嵌的AI询问似乎是个摆设,多次尝试AI均不会给出回复。
代码补全: qoder的代码补全反应灵敏,更新快,能根据实时代码的变化迅速改变推荐的内容。同时,代码补全不局限于行内,对于代码块的预测,也能有较为精准的产出。同时,qoder在待补全的行标前面用弹跳的箭头进行标识,既清楚地标示补全的部分,又不影响打字的流畅度,且能在更改代码之后主动识别出需要协同更改的部分。但补全注释的能力略有不足。
代理模式: Qoder有两种代理模式,一种是常规的对话框,在AI对话框中调用相关模型,协助完成轻量化的任务。可以调用qwen和kimi的部分模型。 另一种是quest模式,这个模式具有较为完整的agent工作流,更专注于释放用户的压力,仅需要用户输入指令,会根据用户指令,自动生成spec,同时,对于用户的模糊问题,还会自动生成问卷,主动帮助用户细化要求,并按照用户的需求生成完整的任务清单。其没有单次输出长度限制,会完整完成所有开发任务。但是在主动进行测试的方面有所不足,没有内嵌主动调试修复的工作流,但是可以在社区的辅助下实现这一功能。此外,虽然完整的spec能基本理解用户的基本需求,但是在部分细节方面不能主动补充完整,这可能是模型的缺陷而非IDE的缺陷。quest模式支持自定义智能体,用户可以根据自己的工作需求,设置属于自己的工作流。 此外,quest支持在有git仓库的情况下,在云端进行运作,此时本地不需要开机或联网,适用于长工作流程的任务。 在修改bug的角度来说,qoder通常可以找到问题并进行修改,修改问题的时候也会主动查询可能有关联的部分一并修改。
定价角度: qoder包含2周的免费使用pro,利于新用户体验这一产品。 对于免费用户,qoder提供无限次的代码补全和行间预测,可以有限地调用基础模型。 对于付费用户,可以解锁quest模式和ropo wiki两大功能,同时获得与套餐等价值的credit(专用货币),根据使用的模型、功能和token数付费。根据官网数据,一次agent协作平均需要消耗0.3元的人民币等值货币,一次quest协作大约需要消耗7元的人民币等值货币。
模型角度: Qoder通常使用qwen系列模型,有时也可以使用kimi系列的模型,但是用户不可以主动确定自己选取的模型,只能通过轻量、经济、性能、极致等等级进行选择
其他维度: Qoder支持常用的windows,mac,linux,同时包含CLI端和jetbrains插件,使用起来方便。 Qoder由国内公司研发,原生支持中英双语。 Qoder的quest模式主动生成spec文档,其ropo wiki模块,总结工程资产并数字化保存,包括工程架构说明,引用关系图谱,技术细节摘要,非常适合团队协作。同时qoder账户中包含teams版本,公司可以方便地管理团队用户和用户开销。
2.5测评对象:copilot(刘诚)
一、IDE简介
Visual Studio Code(简称 VS Code)是由微软开发的一款免费、开源、跨平台的代码编辑器。它不仅是现代软件开发的基础设施,更是连接 GitHub 开源生态的核心枢纽。凭借其轻量级架构与庞大的插件市场,VS Code 几乎统御了当代编程工具的半壁江山。通过与 GitHub Copilot 的深度绑定,VS Code 成功转型为 AI 时代的桥头堡,不仅定义了现代 IDE 的标准形态,更以其无可撼动的生态壁垒,成为了全球开发者事实上的“通用操作系统”。
二、评价概况
- 界面美观:顶级
- 安装配置的耗时:夯
- 学习使用的难度:夯
- 配套社区/插件:夯
- 启动速度:顶级
- 代码补全:人上人
- 功能实现:NPC
- 错误调试:人上人
- 代码重构:人上人
- 多语言支持:夯
- 多平台支持:夯
- 团队协作支持:人上人
- 模型支持:夯
- 使用价格:夯
三、具体评价
界面布局: VS Code 的界面布局堪称教科书级别的“经典”,是无数后起之秀争相模仿的范本。其采用标志性的左侧活动栏、侧边资源管理器、中部编辑区以及底部面板构成的黄金分割布局。这种设计逻辑清晰,功能分区明确,既保证了代码编辑的最大化视野,又兼顾了工具栏的易用性。在 AI 时代,VS Code 巧妙地将 Copilot Chat 侧边栏融入整体布局,既保留了传统编辑器的稳重,又接纳了 AI 交互的灵动。对于任何层次的开发者而言,这种界面都是最熟悉、最符合直觉的交互范式。
使用难度: VS Code 的上手难度极低,安装即用。其最大的优势在于庞大的用户社区与插件生态。无论是面对何种编程语言或冷门框架,用户都能在插件市场中找到对应的解决方案,这种“开箱即用”的体验是其他封闭式 IDE 难以比拟的。社区支持方面,VS Code 拥有全球最活跃的开发者社区,无论是 Stack Overflow 还是 GitHub Issues,任何问题都能在几分钟内找到解决方案。强大的生态赋予了它无限的扩展性,但也意味着用户需要花费精力去筛选和管理插件,配置过程相比一体化产品略显繁琐。
代码补全: 作为 GitHub Copilot 的原生宿主, VS Code 的代码补全体验堪称业界标杆。Copilot 能够深度利用 GitHub 上浩如烟海的开源代码进行训练,提供极具“直觉”的代码建议。它不仅支持行内补全,还能根据函数签名和注释生成整个代码块。Copilot 的建议往往能准确预测开发者的意图,尤其是在处理常规逻辑和样板代码时,效率提升显著。
代理模式: VS Code 原生并不具备 Agent 内核,其代理能力主要通过 Copilot Chat 的“Agent 模式”实现。VS Code 具有优秀的内嵌工作流体验。当 Agent 执行复杂任务时,会将工作流深度嵌入到编辑器的原生前端中。用户可以在侧边栏看到 Agent 自动拆解的 TODO 列表,而在编辑区,Agent 会直接接管文件操作,通过差异对比视图实时展示代码变更。这种“编写-审查-运行”的闭环完全融合在同一个视窗内,用户无需切换应用,即可在代码上下文中直接审视 Agent 的每一步操作,体验直观且高效。
然而,在稳定性方面,VS Code 显露出了其架构上的局限性。首先是网络连接问题,VS Code 在调用大模型时经常遭遇网络超时或连接失败,极大地打断了开发心流。
其次是终端交互的稳定性问题,尤为令人诟病。当 Agent 尝试读取终端输出流或进行长时间监听时,VS Code 极易出现严重的界面卡顿,甚至导致整个应用程序完全失去响应的“死机”现象。这种因终端高负载输出而拖累主线程的死锁问题,深刻暴露了其架构在处理高并发 I/O 时的固有短板。一旦发生,用户往往只能强制结束进程,不仅丢失未保存的状态,更彻底破坏了开发体验,其稳定性远不如 AI 原生 IDE 那般稳健。
定价角度: VS Code 本体完全免费开源,其核心 AI 功能 GitHub Copilot 需要付费订阅。然而,VS Code 最大的价格优势在于其与 GitHub 的深度绑定。通过 GitHub 的学生认证,用户可以免费使用 GitHub Copilot,这不仅解锁了 VS Code 的 AI 潜能,还能免费使用众多顶级大模型,无需额外支付 API 费用。对于学生和教育工作者而言,VS Code 配合 Copilot 无疑是目前市场上性价比最高的开发组合,几乎实现了零成本的顶级 AI 编程体验。
模型角度: 依托于微软与 OpenAI 的战略合作以及 GitHub 的生态优势,VS Code 中的 Copilot 集成了业界最顶尖的模型资源。
其他维度: VS Code 拥有目前最庞大的插件市场,覆盖 from 开发、调试到部署的全生命周期,其生态壁垒短期内难以被超越。其内置的 Git 管理功能强大直观,Remote Development 远程开发能力更是独步江湖。支持 Windows、Mac、Linux 全平台,真正实现了开发环境的无缝迁移。
2.6 测评对象:windsurf(刘诚)
一、IDE简介
Windsurf 是由 Codeium 团队倾力打造的一款 AI 原生 IDE,被誉为世界上第一个"Agent IDE"。它并未止步于简单的代码生成工具,而是通过深度集成开发环境,旨在实现开发者与 AI 的"心流"协作。Windsurf 凭借独创的"Flux"引擎,打破了聊天窗口与代码编辑器的界限,让 AI 能够真正理解开发者的意图与操作环境。它不仅能够流畅地生成代码,更通过"流式上下文"感知与"内嵌工作流"的深度协同,重新定义了人机协作的编程体验,让开发者能够沉浸在创造性的工作中,而非被琐碎的打断所困扰。
二、评价概况
- 界面美观:人上人
- 安装配置的耗时:夯
- 学习使用的难度:顶级
- 配套社区/插件:NPC
- 代码补全:夯
- 功能实现:夯
- 错误调试:夯
- 代码重构:顶级
- 多语言支持:顶级
- 多平台支持:顶级
- 团队协作支持:顶级
- 模型支持:顶级
- 使用价格:人上人
三、具体评价
界面布局: Windsurf 在视觉上沿用了经典 VS Code 的布局风格,对于习惯传统开发环境的用户来说几乎零门槛。其核心创新在于界面功能的深度融合,并没有生硬地将 AI 对话框与编辑器割裂。主界面中,AI 功能并非仅局限于侧边栏,而是通过 Command-K 等快捷指令直接在代码编辑区唤起交互。Windsurf 的设计哲学是"AI 即编辑器",用户无需在多个面板间频繁切换,所有的建议、修改和对话都在当前的代码上下文中自然流淌。这种布局极大地保持了开发者的专注度,让界面服务于心流。
使用难度: Windsurf 的上手体验极为丝滑,支持一键从 VS Code 导入设置、插件和主题,几乎实现了无缝迁移。在社区支持方面,Codeium 的主要活跃社区位于 Discord。这对于国内用户而言存在一定的门槛,需要使用特殊的网络工具才能访问,且全英文的交流环境对部分用户也是一种挑战。不过,其内置的 AI 助手响应迅速,对于操作层面的疑问能给出准确的指引,在日常使用中能弥补社区访问不便带来的缺憾。
代码补全: Windsurf 的代码补全能力是其核心亮点之一,特别是其对"流式上下文"(Flow Context)的极致运用。不同于传统 IDE 仅基于当前文件或光标位置进行补全,Windsurf 的 Flux 引擎能够实时感知开发者的操作流。它不仅反应极快,能根据最新的代码改动即时调整预测,更具备跨文件的上下文理解能力。当开发者在 A 文件定义类型,在 B 文件调用时,Windsurf 能精准感知这种关联,给出符合整体架构逻辑的建议。此外,它的补全不局限于代码,对于复杂的注释逻辑和文档字符串也能精准生成。最令人印象深刻的是其"感知"能力,当你在终端运行命令报错时,补全系统会立即"意识"到错误上下文,主动提供修复建议的代码块,真正实现了代码补全从"被动预测"向"主动流式协同"的跨越。
代理模式: Windsurf 的代理模式通过"Cascade"功能实现,其核心在于"内嵌工作流"(Embedded Workflows),这是一种将 AI 智能体无缝编织进开发循环的创新模式。不同于其他工具将 Agent 作为一个独立的助手或弹窗,Windsurf 的 Cascade 实现了真正的"环境内嵌"。当用户提出一个复杂需求时,Agent 首先会利用其强大的 RAG 能力,在后台无感地对整个代码库进行索引和语义检索,构建完整的上下文图谱。接着,它会直接在编辑器中展示一个详细的"待办清单"(Todo List),清晰列出即将执行的所有步骤。最为关键的"内嵌"体现在执行环节:Agent 会直接操作用户的文件系统,在侧边栏实时展示文件的 Diff 变化,用户可以清晰地看到代码被一行行修改的过程。如果遇到需要安装依赖或运行测试,Agent 会直接唤起底部的终端面板,执行命令并读取输出结果。如果测试失败,它会根据报错信息自动迭代修复代码,形成一个"生成-执行-调试-修复"的完整闭环。这种工作流完全融入在 IDE 的原生平铺视图中,用户无需切换视窗,即可见证任务从指令到落地的全过程。
定价角度: Windsurf 采用订阅制基础上的按条收费模式(基于 Action Points 或类似机制)。虽然订阅提供了基础额度,但对于高频使用 Agent 的用户来说,点数的消耗需要精打细算。因此,推荐用户在使用 Cascade 代理模式时,尽量一次性详细地给出所有需求和约束条件,避免因需求不明确导致的反复迭代和多次交互,从而有效减少开支。这种定价策略在一定程度上倒逼用户提升 Prompt 的质量,但也增加了试错的成本。
模型角度: Windsurf 背后依托 Codeium 强大的模型适配能力,集成了业界顶尖的三大模型系列:GPT 系列、Google Gemini 系列以及 Anthropic Claude 系列。Codeium 团队在模型跟进上展现了惊人的速度,特别是在 Claude Opus 4.6 发布的当天,Windsurf 就第一时间完成了集成支持。
其他维度: Windsurf 支持 Windows、Mac 和 Linux 全平台,作为 VS Code 的深度分支,其插件生态完全兼容,用户可以继续使用自己熟悉的 Vim、Theme 等插件。此外,Windsurf 的多语言支持完善,原生支持中英双语交互。其内嵌工作流所产生的操作记录清晰可见,方便团队复盘,非常适合个人开发者和小型敏捷团队尝试这一全新的开发范式。
2.7 测评对象:cursor(张乐恒)
一.IDE简介
Cursor 是由 Anysphere 团队打造的一款颠覆性 AI 代码编辑器。它是基于 VS Code 的 Hard Fork 版本,但在底层逻辑上进行了 AI 原生重构。不同于简单的插件叠加,Cursor 凭借其独家的上下文索引技术和 Shadow Workspace 机制,能够让 AI 真正“看懂”整个项目。它不再只是一个代码补全工具,而是致力于成为程序员的“结对编程”伙伴,重新定义了人机协作的开发效率上限。
二.评价概要:
- 界面美观:NPC
- 安装配置的耗时:夯
- 学习使用的难度:夯
- 配套社区/插件:夯
- 启动速度:夯
- 多项目切换:顶级
- 代码补全:顶级
- 功能实现:顶级
- 错误调试:夯
- 代码重构:顶级
- 多语言支持:夯
- 多平台支持:顶级
- 团队协作支持:夯
- 模型支持:顶级
- 使用价格:npc
三.具体评价:
界面布局: Cursor 聪明地保留了 VS Code 的经典布局,这使得全球数千万开发者几乎零成本迁移。它在原生体验的基础上无缝嵌入了 AI 能力。用户可以通过 Cmd/Ctr+J 在代码行间直接呼出指令框,或通过 Cmd/Ctr+L 呼出侧边栏对话。
使用难度: 配置极度简化,Cursor 提供了“一键迁移”功能,安装后首次启动即可自动同步用户在 VS Code 中的所有插件、主题和快捷键设置,真正做到上手即用。 在社区方面,Cursor 拥有极其活跃的全球社区,开发者不仅分享 Prompt 技巧,还通过 .cursorrules 文件分享特定技术栈的 AI 行为规范。 其官方文档清晰详尽,且由于其基于 VS Code,几乎所有 VS Code 的生态文档都通用,新手的学习曲线极低。
代码补全: Cursor 的代码补全(被称为 Cursor Tab)是目前业界的标杆。它不局限于“补全当前行”,而是具备强大的预测能力,能够根据光标位置和最近的修改习惯,预测用户接下来的“改动意图”。 它支持多行甚至跨块的补全,反应极快。在实测中,当你修改了一个变量名,Cursor 往往能预判到你接下来要去修改引用该变量的另一行代码,并直接按 Tab 键即可应用修改。它用灰色的文本展示建议,既直观又不打扰思维流,且准确率惊人,极大减少了 Tab 键之外的按键次数。
第三部分:实战Demo展示
为了验证AI IDE在真实开发场景中的表现,我们设计了三个不同维度的测试案例,分别考察逻辑构建能力、创意实现能力以及大型项目重构能力。
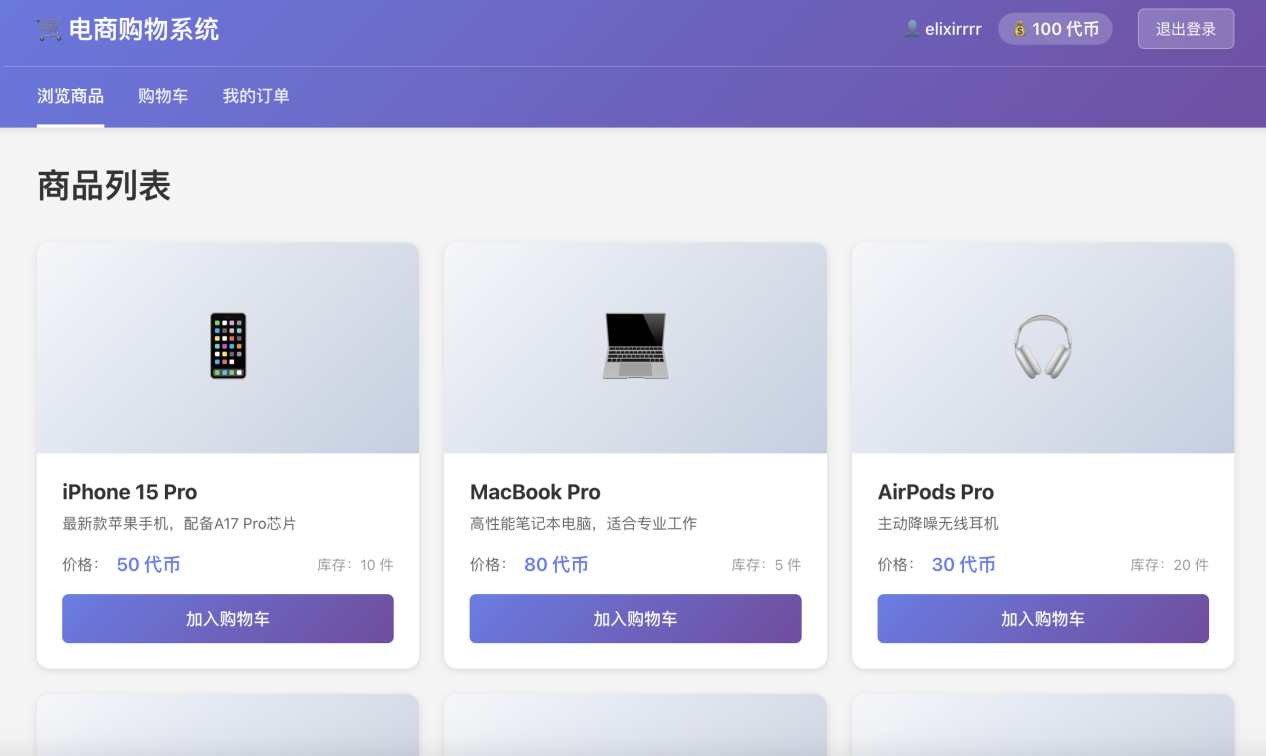
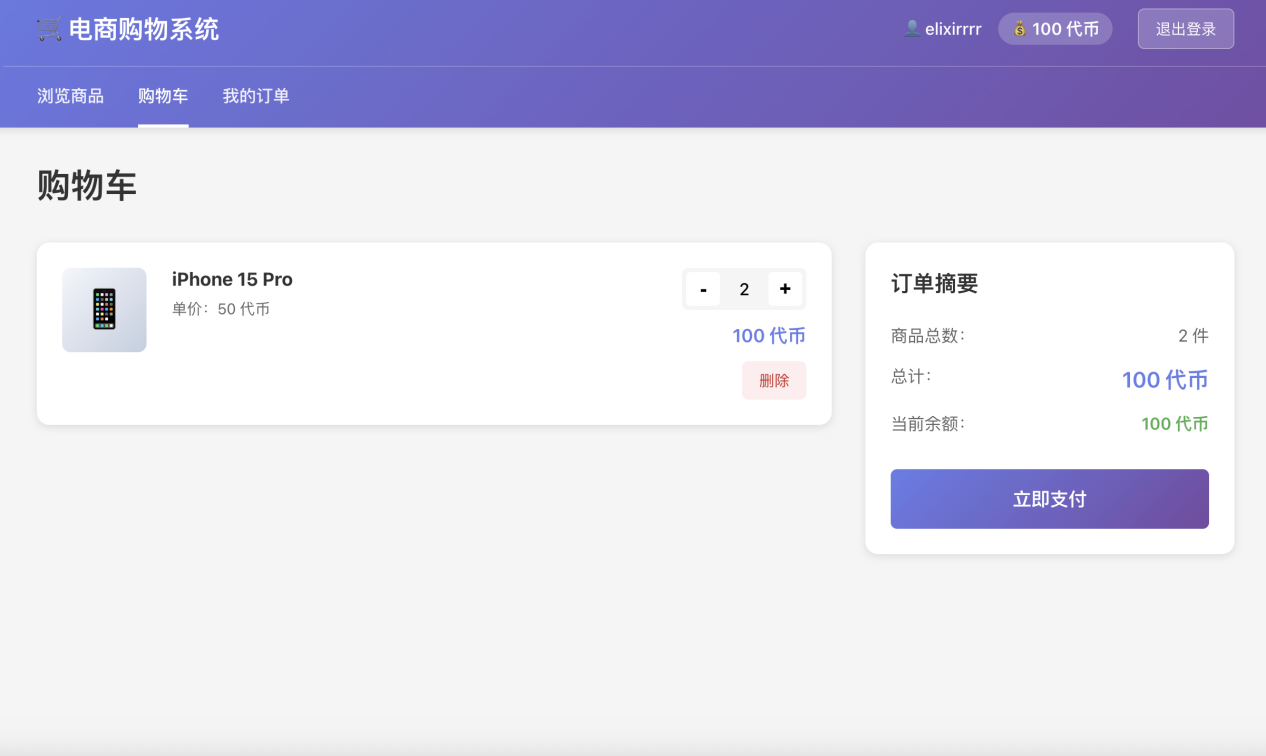
3.1 Demo 1:模拟电商购物系统
测试目的:考察AI对复杂业务逻辑的理解能力、数据结构的设计能力以及基本的前后端交互实现。任务描述:要求AI从零构建一个简易的电商购物系统,需包含以下核心功能:
- 商品展示:展示商品列表(图片、价格、名称)。
- 购物车逻辑:添加商品、移除商品、数量增减、实时计算总价。
- 模拟结算:模拟订单生成与支付流程。 Trae国内版
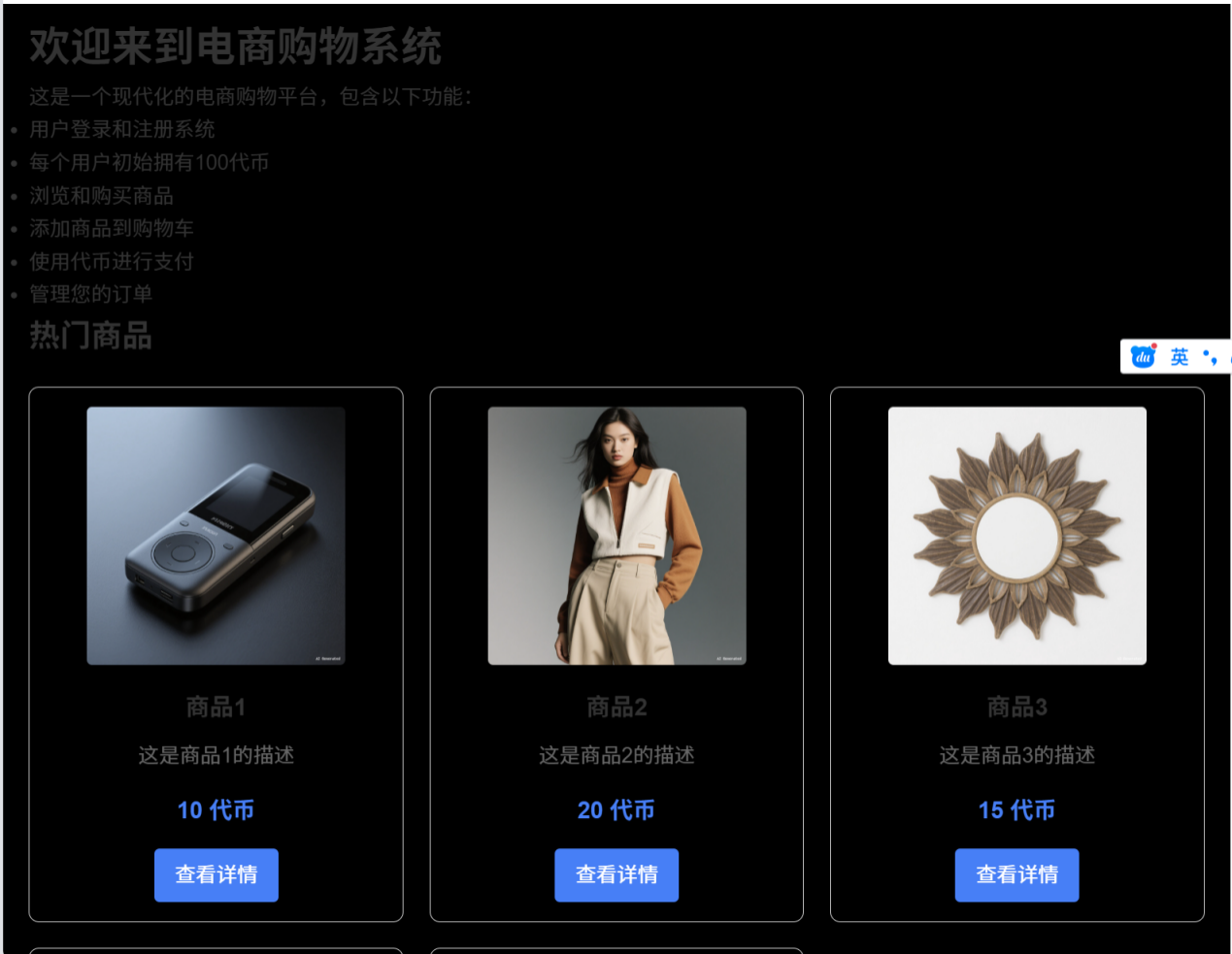 这是Trae做的电商平台这是已用虚拟账号登录的页面,可以点击商品并加入购物车,虽然画质不是很美观(原来的登录系统有问题,在多次修改后画面变难看了)
这是Trae做的电商平台这是已用虚拟账号登录的页面,可以点击商品并加入购物车,虽然画质不是很美观(原来的登录系统有问题,在多次修改后画面变难看了)
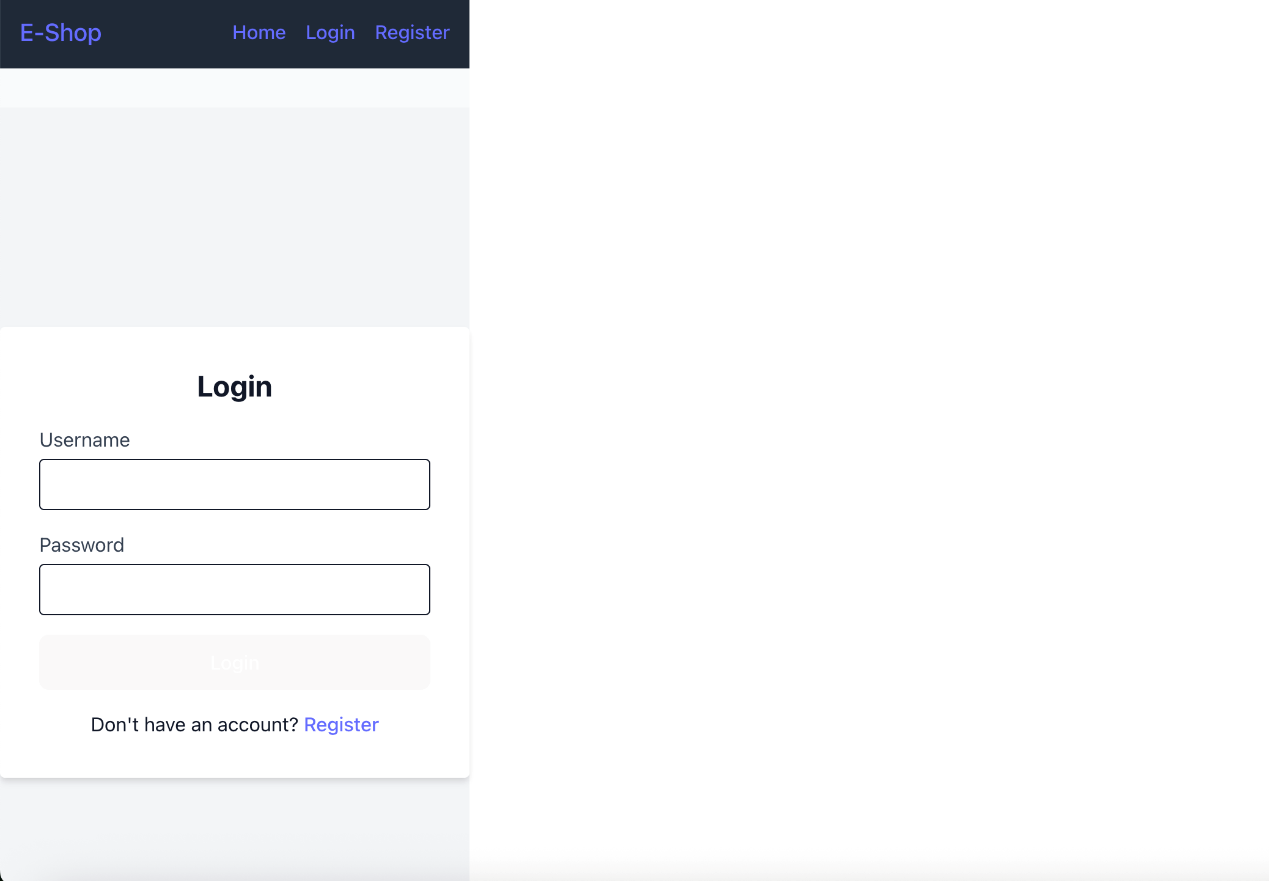
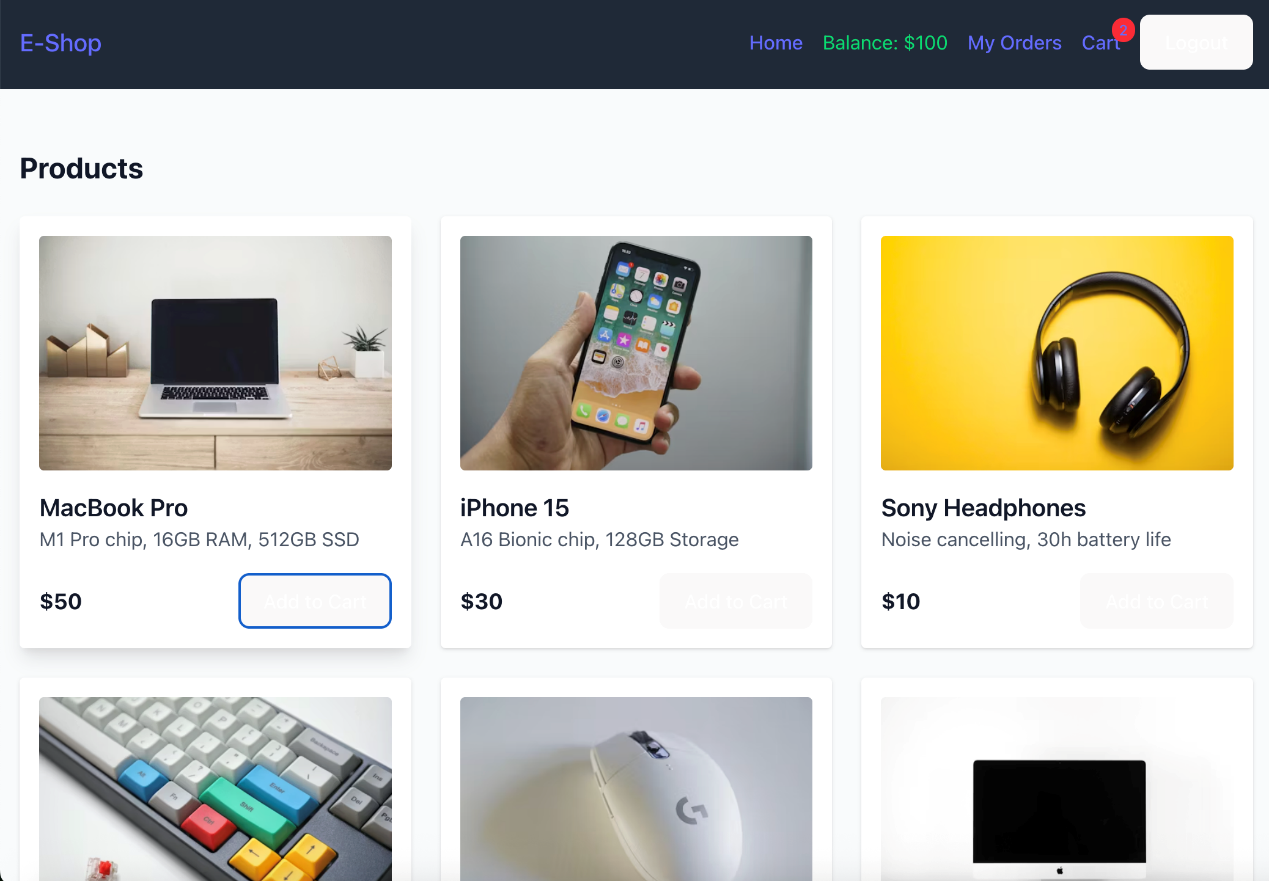
Trae国际版 Propmt:制作一个电商购物系统,包含用户登录系统,用户初始包含100代币,包含浏览商品,加入购物车,模拟支付(通过支付代币),管理订单的功能 Trae最开始出现了图片引用的问题,引用的两张实例图片失效了,说明其联网搜索的能力有待提升。经过提示后修改结果如下,作为网页端来说平登录界面留白有些多,但是这个图片质量和UI质量值得点赞。
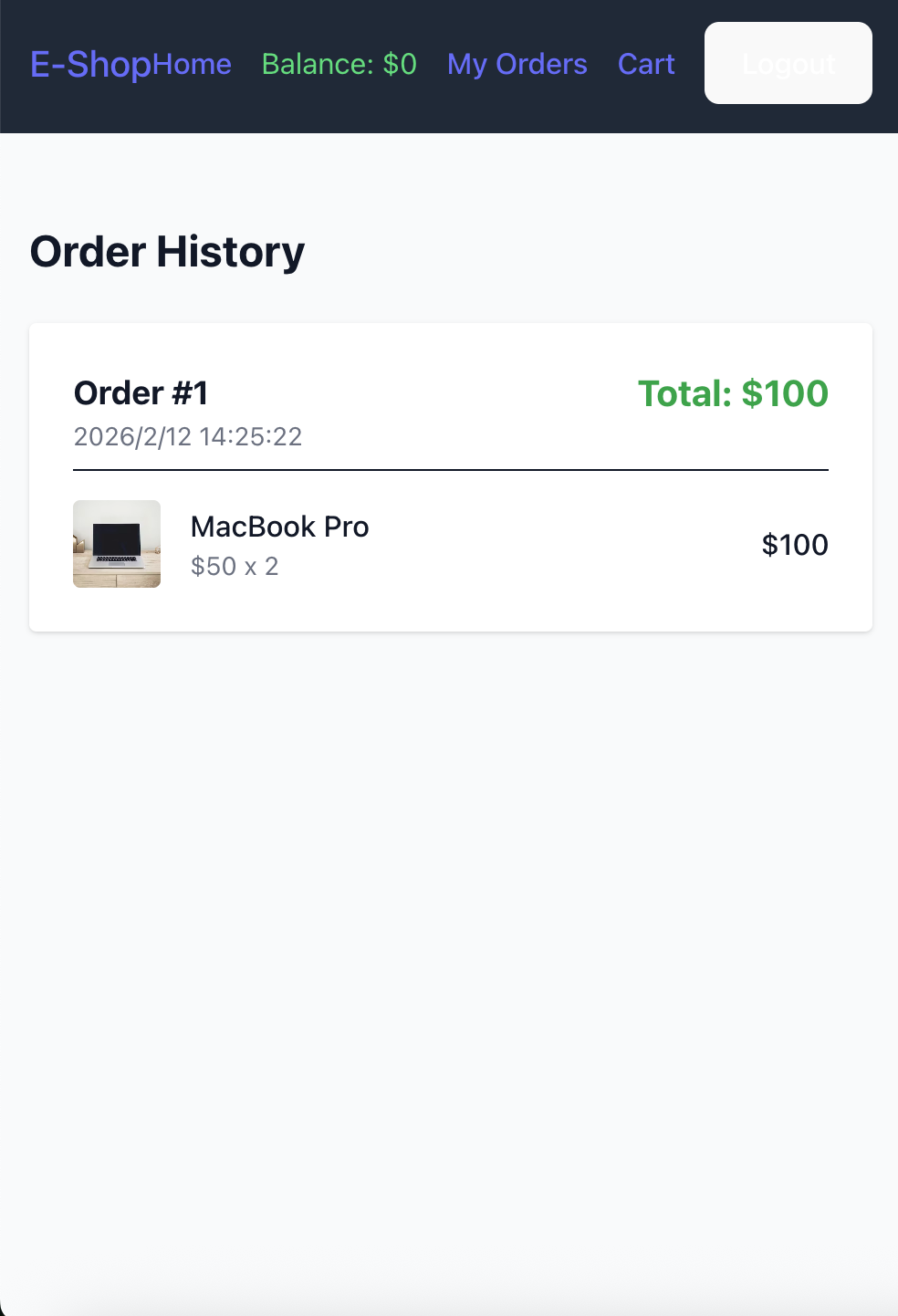
通义灵码
 这是通义灵码的电商平台登录后的购物车页面,已经加入了两件商品,在修复错误时其反复进行同一操作,最后经过多轮对话发现问题(在Editor测试下难以发现问题,最后正确运行但不稳定,时灵时不灵,最后切换为Quest模式才终于解决.
这是通义灵码的电商平台登录后的购物车页面,已经加入了两件商品,在修复错误时其反复进行同一操作,最后经过多轮对话发现问题(在Editor测试下难以发现问题,最后正确运行但不稳定,时灵时不灵,最后切换为Quest模式才终于解决.
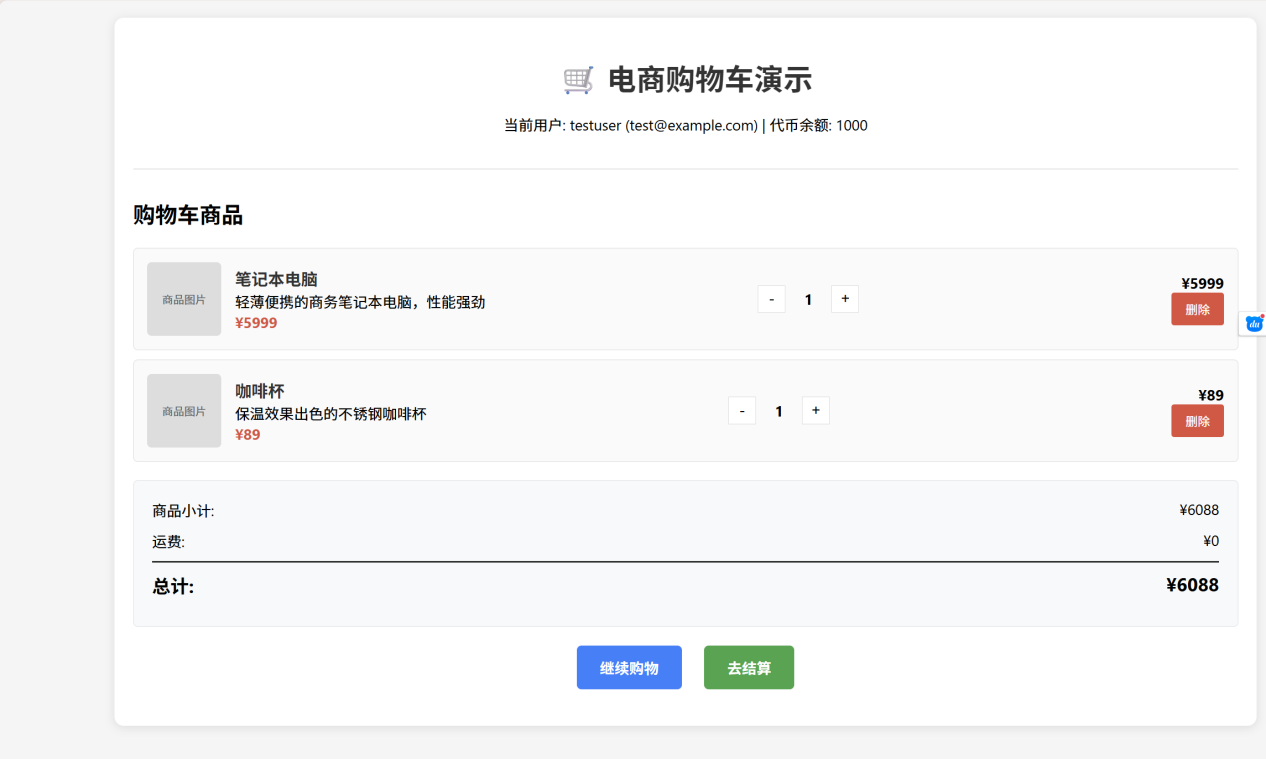
Qoder 作为纯功能实现的任务,qoder在quest模式的支持下有良好的表现,会主动生成详细工作流程,但是对任务理解不够深刻,第一次完成的时候购买物品之后库存不会减少,但是在提出bug之后迅速改正。这也体现出qoder内嵌工作流在测试方面的缺乏。
Windsurf
 Windsurf在工作完成方面非常出色,只需要少量的提示词就能形成完善的成品,且能自主测试,保证完成度。美中不足的是,windsurf的审美太差了。界面非常丑陋。
Windsurf在工作完成方面非常出色,只需要少量的提示词就能形成完善的成品,且能自主测试,保证完成度。美中不足的是,windsurf的审美太差了。界面非常丑陋。
Cursor
Cursor一次就实现了以下的功能,并且可以看到这个美术设计还是比较精致的。
3.2 Demo 2:模仿《植物大战僵尸》制作游戏
测试目的:考察AI在创意性项目中的表现,包括Canvas/游戏引擎的使用、动效处理、游戏循环逻辑以及对象管理能力。 任务描述:要求AI模仿经典游戏《植物大战僵尸》制作一个简易版Demo:
- 核心玩法:实现“植物”种植、“僵尸”自动移动与攻击逻辑。
- 交互设计:阳光收集机制、卡片选择与放置。
- 胜负判定:僵尸到达终点失败,全消灭胜利。
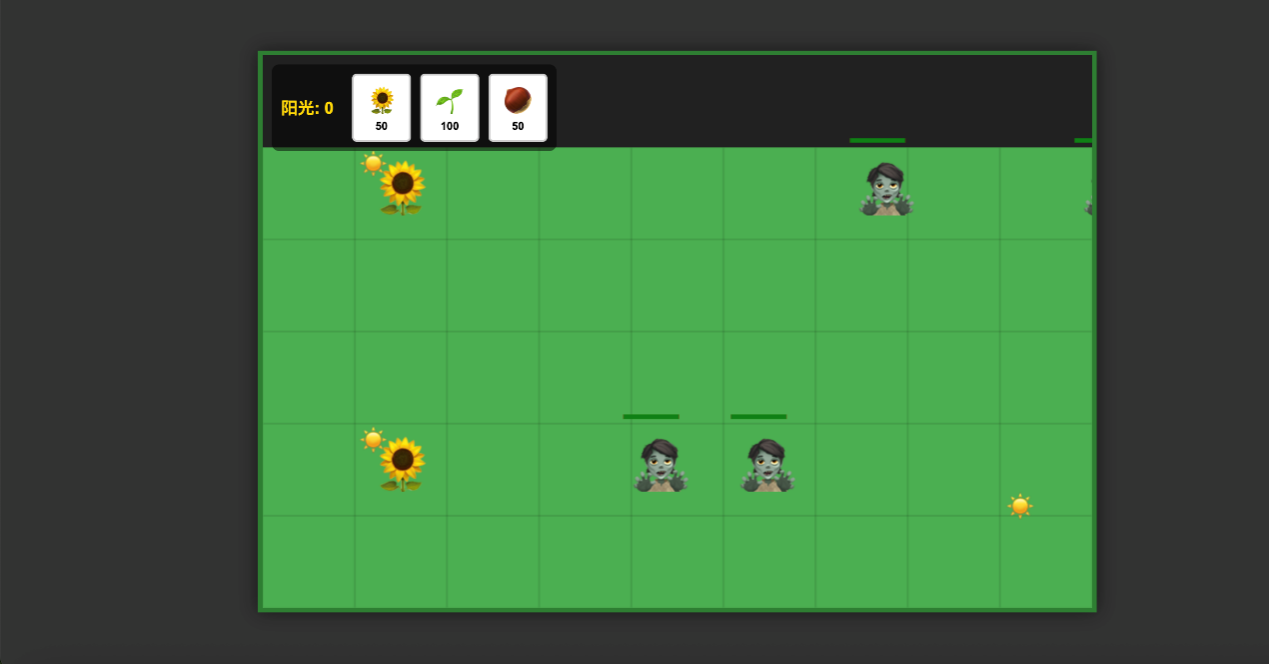
Trae国内版
 这是Trae做的植物大战僵尸,在玩家策略适当时可以顺利拿下,一开始做的在僵尸到达最左侧时只能种两个坚果,难以进行,对话后理解并按要求修改
这是Trae做的植物大战僵尸,在玩家策略适当时可以顺利拿下,一开始做的在僵尸到达最左侧时只能种两个坚果,难以进行,对话后理解并按要求修改
Trae国际版 Trae值得夸赞的是用很少的时间 and 很短的代码就实现了pvz的基本玩法,代码量是cursor实现的一半,并且一次成功,可以看出其流线型编程设计的底蕴。
 通义灵码
通义灵码
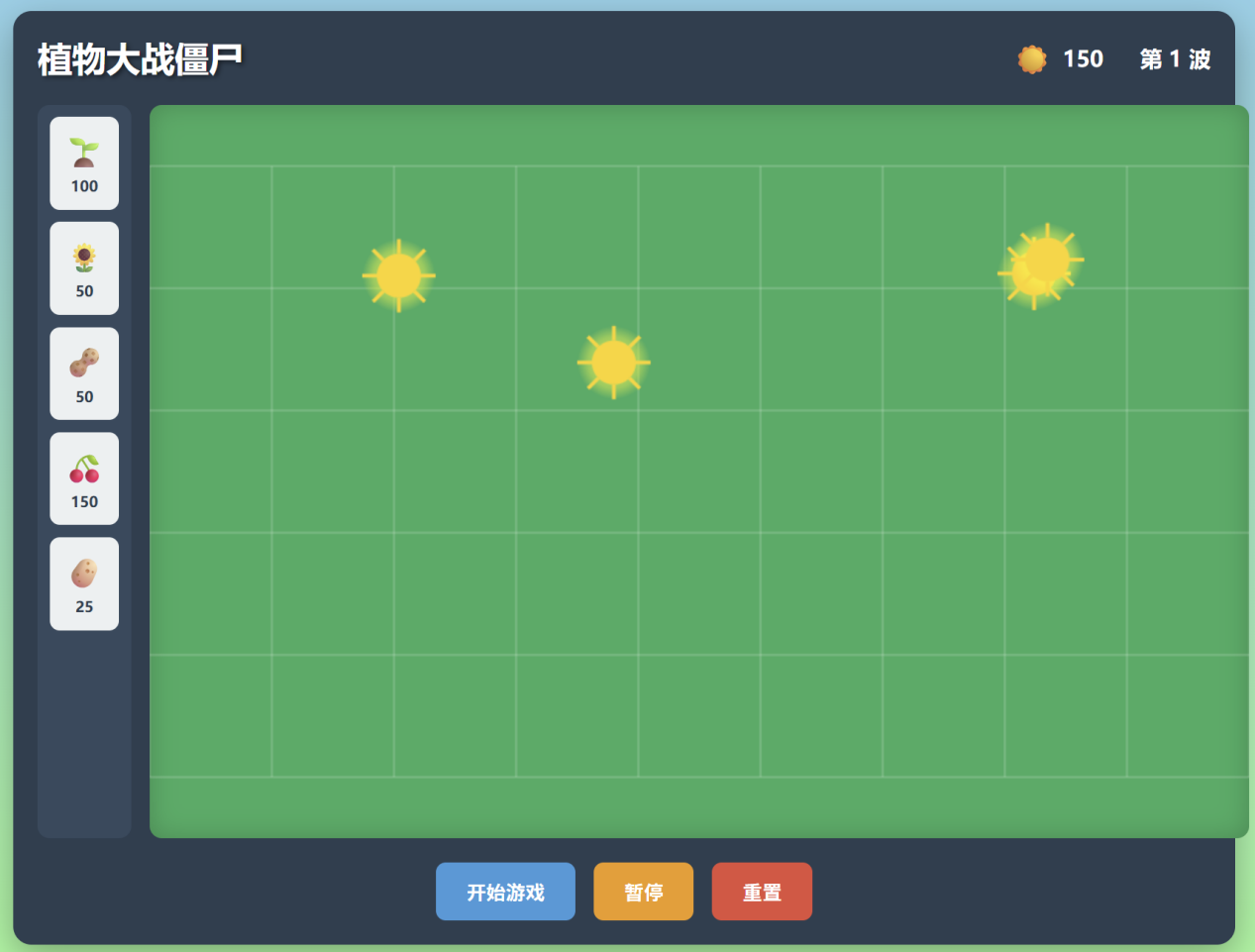 这是通义灵码做的植物大战僵尸,较有难度,植物种类也比较多,虽然图片可能不是很明显的表现了植物种类(缺少美术资源)(两种模式均完成很好)
这是通义灵码做的植物大战僵尸,较有难度,植物种类也比较多,虽然图片可能不是很明显的表现了植物种类(缺少美术资源)(两种模式均完成很好)
Qoder
 Qoder做的植物大战僵尸应该是所有demo中可玩性最高的,游戏平衡控制的很好,而且内容量也很大,同时又提示词简单,这反映了qoder在quest模式中针对创意落地的方向下的功夫。
Qoder做的植物大战僵尸应该是所有demo中可玩性最高的,游戏平衡控制的很好,而且内容量也很大,同时又提示词简单,这反映了qoder在quest模式中针对创意落地的方向下的功夫。
Windsurf
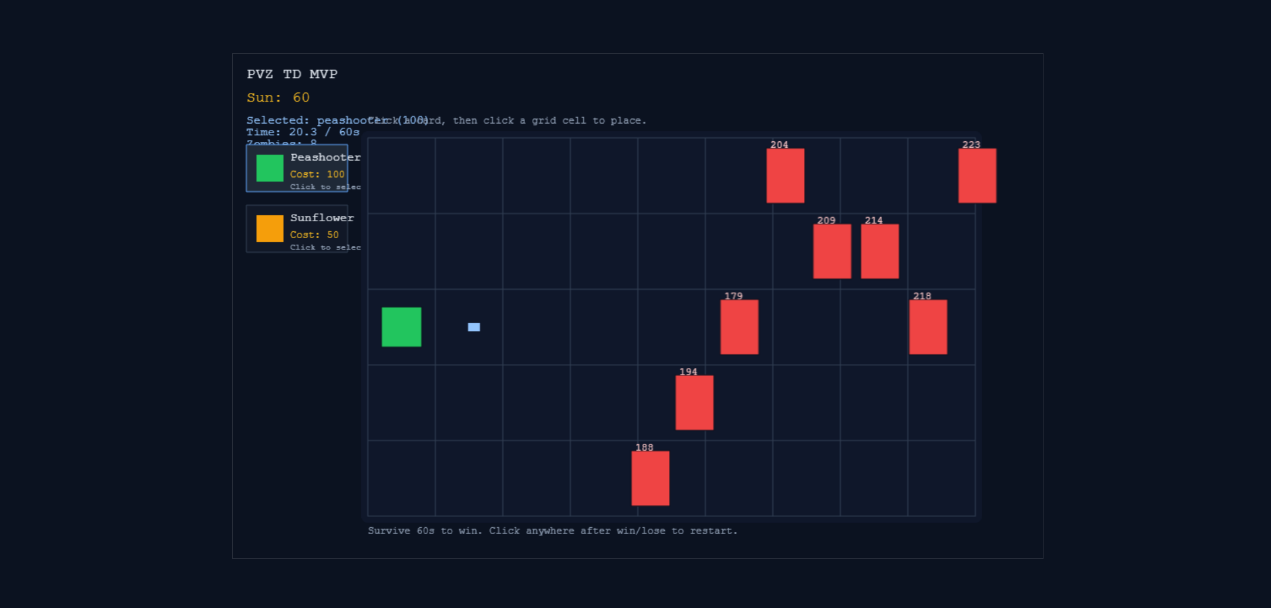 Windsurf的审美一如既往地差,而且功能非常简单,平衡性也一般,但是游戏本身没有出任何bug。
Windsurf的审美一如既往地差,而且功能非常简单,平衡性也一般,但是游戏本身没有出任何bug。
Cursor Prompt:帮我生成一个植物大战僵尸的小游戏
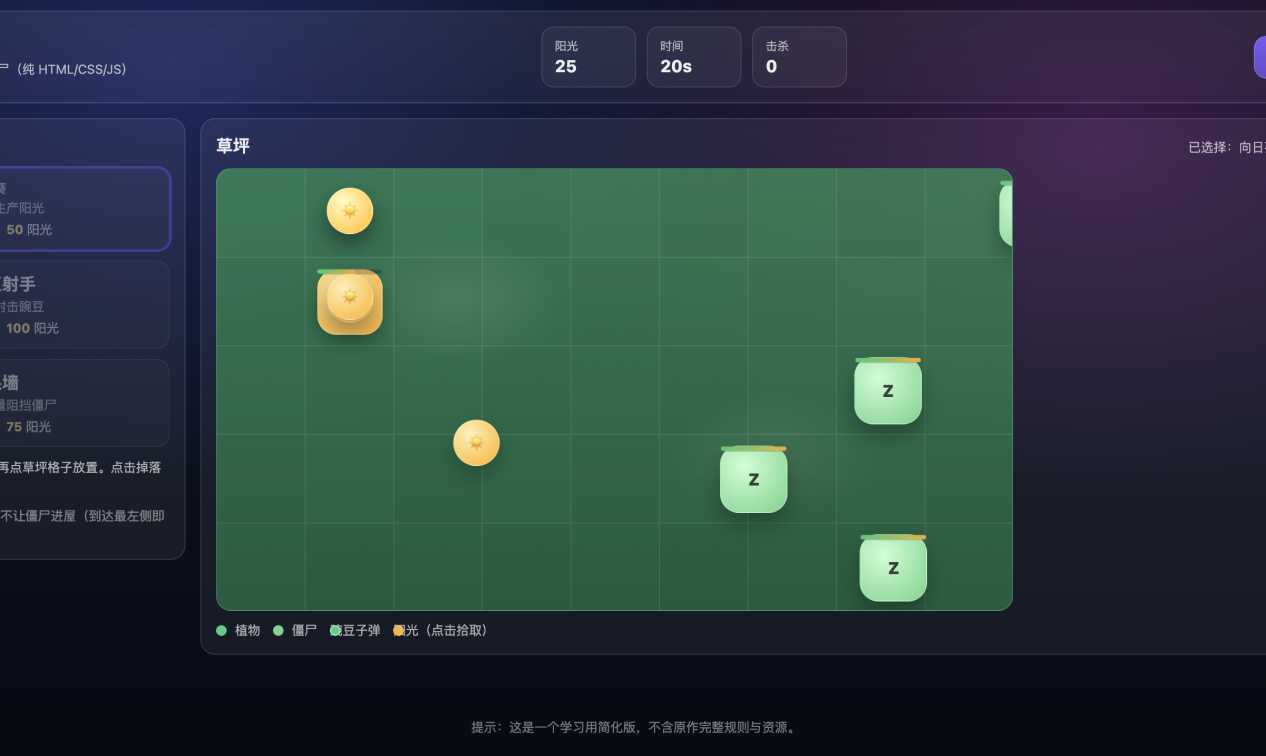
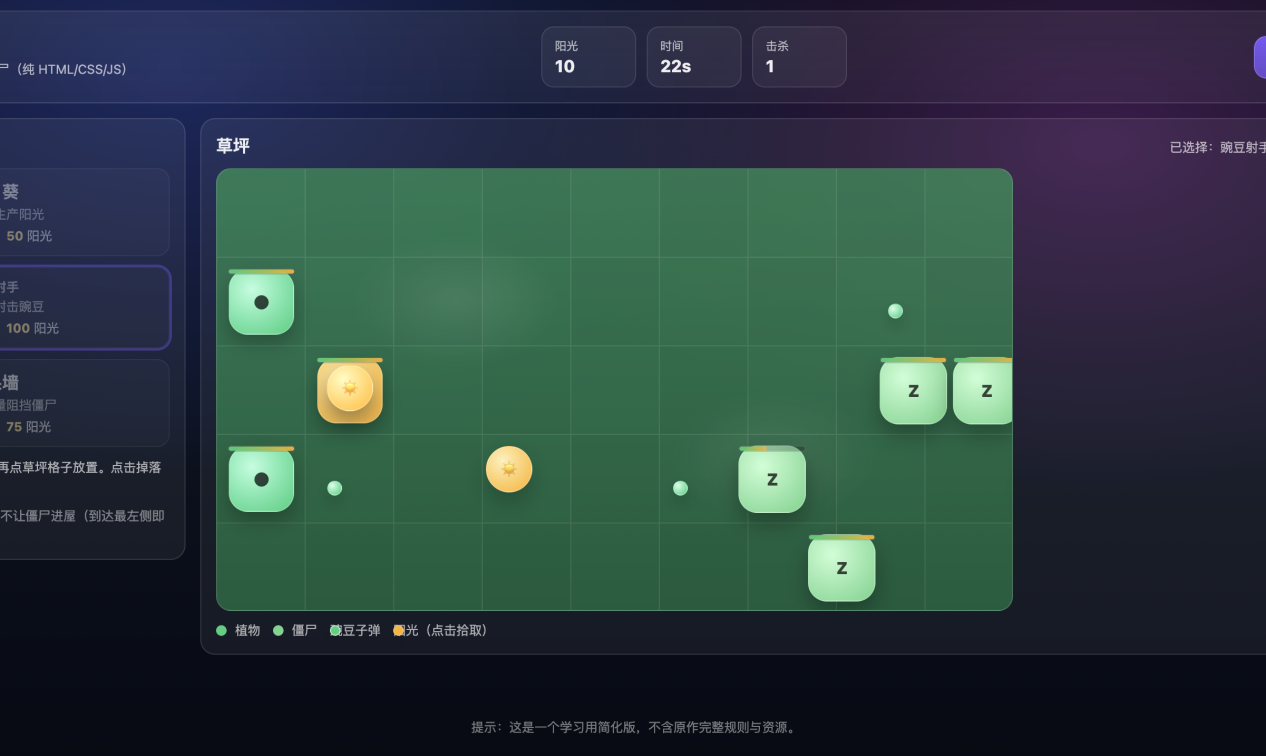
很快生成好了大致的游戏结构,但是玩法是不正确的,可以看到僵尸在距离向日葵有一段距离的时候向日葵的血量下降了,后来发现是代码逻辑错误,认为僵尸在向日葵同一行左侧就扣血,经过提示修改,效果恢复正常。
3.3 Demo 3:开源项目Excalidraw深度修改
测试目的:考察AI IDE对大型、复杂开源项目的代码理解能力、跨文件重构能力以及上下文感知能力。 项目背景:Excalidraw是一个基于TypeScript的虚拟白板工具,TypeScript类型定义严格,代码耦合度高,适合作为高难度测试样本。 环境准备: 由于国内网络环境限制,测试前需完成项目克隆与依赖安装(建议通过配置Git代理或下载ZIP包解决GitHub连接问题),确保 yarn start 可成功启动项目。 测试用例 1:全库检索与“幻觉”测试 · 任务:询问Excalidraw画布默认背景颜色的定义位置,并尝试修改为淡蓝色 #e6f7ff。 · 考察点:AI是否真的阅读了代码库,而非编造通用的CSS方案。 测试用例 2:核心接口重构 · 任务:为核心接口 ExcalidrawElement 增加新字段 authorName,并要求AI处理所有创建新元素、复制元素及数据恢复的逻辑,确保TypeScript编译不报错。 · 考察点:这是分水岭级别的测试。普通IDE可能只修改定义而导致全项目报错,顶级IDE应能自动修改所有引用点。 测试用例 3:新功能开发 · 任务:在顶部工具栏增加“统计”按钮,点击后弹出Alert显示当前画布元素总数,并复用现有UI风格。 · 考察点:考察AI对UI组件库的熟悉程度及对App State状态的读取能力。
Trae国内版
 亮起的按键即为统计按键,一开始Trae没有将其添加到工作栏中,调整时出现错误,其反复生成文件,花费较长时间修复6个错误,在进行重构时漏了复制函数导致报错,其他表现良好
亮起的按键即为统计按键,一开始Trae没有将其添加到工作栏中,调整时出现错误,其反复生成文件,花费较长时间修复6个错误,在进行重构时漏了复制函数导致报错,其他表现良好
Trae国际版
这是本次 Excalidraw 测试中欠缺的部分。Trae 的 Agent 表现出“过度工程化”的特征:
· 重构任务(Refactoring): 在 Task 2(添加字段)中,Trae 初次修改遗漏了关键文件(如 restore.ts),评分 3.8/5。 但在自我修复环节,它遭遇了滑铁卢。当用户甩回报错后,Trae 陷入了死循环。它试图自主运行测试 -> 报错 -> 尝试修复 -> 再运行测试 -> 再报错。这种“陷入终端测试出不来”的现象,说明其 Agent 的“停止机制”和“错误反思能力”尚不成熟。它试图完美解决所有问题,却因无法处理复杂的测试环境配置而卡死。 · 新功能开发(Feature): 在 Task 3(Toolbar 统计按钮)中,Trae 虽然成功完成了任务,但过程极其低效。 o Cursor: 并在几秒钟内定位文件 -> 生成 UI -> 结束。 o Trae: 生成了大量的临时测试文件,思维链极长,反复验证逻辑。虽然最终结果是好的,但耗时是 Cursor 的数倍。这给人的感觉是“用力过猛”——杀鸡用牛刀,导致开发流畅度大打折扣。
通义灵码
 最左侧按键右边增加的按键就是统计,点开之后会遮挡按键,所以没有展示,通义灵码Quest一次完成了工作,而同一测试集中Editor在第一步就没能通过,未能真正读取代码,而是返回常规CSS代码
最左侧按键右边增加的按键就是统计,点开之后会遮挡按键,所以没有展示,通义灵码Quest一次完成了工作,而同一测试集中Editor在第一步就没能通过,未能真正读取代码,而是返回常规CSS代码
Qoder
 (请忽略测试人员抽象的画作)可以看出,除了quest模式下的完整工作流,qoder常规对话框的能力也是很高的,其完美地理解了要求,每次都能一步到位实现需求,而且不出错,icon的统一度也很高,这一定程度上让测试人员对如何评价其修改错误的能力感到头疼
(请忽略测试人员抽象的画作)可以看出,除了quest模式下的完整工作流,qoder常规对话框的能力也是很高的,其完美地理解了要求,每次都能一步到位实现需求,而且不出错,icon的统一度也很高,这一定程度上让测试人员对如何评价其修改错误的能力感到头疼
Copilot
 Copilot确实实现了功能,在忽略其网络连接波动带来的重试下,其也是一次完成任务,不需要反复修改。不过,其内置了测试的工作流,但是其读取终端和判断退出的能力非常之差,严重影响了工作效率。在网络连接稳定的情况下,其完成相同任务的耗时也在windsurf的2倍。
Copilot确实实现了功能,在忽略其网络连接波动带来的重试下,其也是一次完成任务,不需要反复修改。不过,其内置了测试的工作流,但是其读取终端和判断退出的能力非常之差,严重影响了工作效率。在网络连接稳定的情况下,其完成相同任务的耗时也在windsurf的2倍。
Windsurf
 第三次吐槽windsurf的审美,采用巨大的黑体字作为统计图标。不过其功能实现快,效果稳定,一步到位。
第三次吐槽windsurf的审美,采用巨大的黑体字作为统计图标。不过其功能实现快,效果稳定,一步到位。
Cursor
A. 重构能力 (Refactoring): 拉开差距的分水岭
· 任务: 给核心接口 ExcalidrawElement 增加 authorName 字段,要求所有新元素默认为 “Anonymous”,并兼容旧数据。
标准模式 (Low Mode) 表现:4/5 (有瑕疵) · 结果: 任务勉强完成,但存在“硬伤”。 · 失误详情(Anonymous 字段处理):
- 硬编码风险: AI 虽然修改了接口,但在初始化时直接在几个主要工厂函数里硬编码了字符串 “Anonymous”,而不是将其提取为常量或在基类中统一处理。
- 覆盖不全: 漏掉了 duplicateElement(复制元素)或某些偏门的工厂函数,导致用户在复制一个旧元素时,authorName 可能会丢失或变成 undefined。
- 兼容性被动: 虽然代码能跑,但没有主动去修 restore.ts,旧数据打开时可能会有隐患。 · 结论: 能用,但像个“初级程序员”,写出的代码需要人工 Code Review 和二次修改。
高阶推理模式 (High-Reasoning) 表现:5/5 (God Tier) · 结果: 完美无瑕,一次性通过。 · 表现详情:
- 抽象思维(懂架构): 它精准识别了工厂模式,直接在基类函数 _newElementBase (src/element/newElement.ts) 中统一使用了 rest.authorName ?? “Anonymous” 进行初始化。一处修改,全局生效。
- 数据迁移(懂兼容): 展现了惊人的工程经验,预判到旧文件打开时会缺少该字段,主动在数据恢复逻辑 restoreElementWithProperties (src/data/restore.ts) 中添加了兼容代码。
- 打破盲区(懂测试): 最令人震撼的是,它主动扫描并修复了 tests/fixtures 下的硬编码测试数据。 · 结论: 这是一个“高级工程师”的水平,具备防御性编程思维。
B. 新功能开发 (Feature): 5/5 (Perfect)
· 任务: 在 Toolbar 增加“统计”按钮,复用现有 UI。 · 表现详情: o 无论是标准模式还是推理模式,Cursor 都能精准定位组件库位置 (src/components/Toolbar.tsx)。 o UI 复用: 完美复用了 Excalidraw 内部的 和 组件,样式与原项目完全一致。